Random vs. Systematic Failures in Functional Safety and the Crucial Role of SIL
In the world of industrial automation and safety-critical systems, the silent sentinels of functional safety stand guard, protecting against catastrophic events. These systems, whether in a sprawling chemical plant, a complex power grid, or a sophisticated medical device, are designed to prevent harm to people, the environment, and assets. But what happens when these guardians falter? The answer lies in understanding the two fundamental types of failures that can plague any safety system: random failures and systematic failures. Distinguishing between these two is not just an academic exercise; it’s a cornerstone of achieving a robust and reliable safety posture, quantified and qualified by the Safety Integrity Level (SIL).
This comprehensive blog will delve deep into the nuances of random and systematic failures, exploring their origins, characteristics, and mitigation strategies. We will demystify the concept of SIL and illustrate how it provides a structured framework for managing both types of failures, ensuring that our safety systems are not just designed to be safe but are demonstrably safe throughout their entire lifecycle.
The Predictably Unpredictable: Understanding Random Hardware Failures
Random hardware failures are the easier of the two to grasp. As the name suggests, they occur at unpredictable moments in time, stemming from the physical degradation of hardware components. Think of it as the wear and tear on your car; you know that eventually, a part will fail, but you can’t pinpoint the exact moment it will happen.
These failures are probabilistic in nature. We can’t predict the failure of a single component, but we can statistically estimate the failure rate of a population of similar components based on historical data. This is analogous to how actuaries predict life expectancy; they can’t tell you when an individual will pass away, but they can provide a statistical average for a demographic group.
Characteristics of Random Failures:
Time-Dependent: They are a function of the operational time and stress factors experienced by the component.
Hardware-Related: They are exclusive to physical components like sensors, actuators, logic solvers, and wiring.
Unpredictable at the Individual Level: The exact moment of failure for a specific component cannot be foreseen.
Quantifiable: Their likelihood can be expressed in terms of a failure rate (e.g., failures per million hours).
Mitigated by Redundancy and Diagnostics: If one component fails, a backup can take over, or a diagnostic system can detect the failure and initiate a safe state.
Causes of Random Failures:
The root causes of random failures are intrinsic to the physical world:
Component Aging: The natural degradation of materials over time.
Environmental Stress: Operation outside of specified temperature, humidity, or vibration limits.
Manufacturing Defects: Imperfections introduced during the production of a component.
External Events: Power surges, lightning strikes, or physical impact.
A Simple Block Diagram of a Random Failure:
Imagine a simple Safety Instrumented Function (SIF) designed to prevent a tank from overfilling. It consists of a level sensor, a logic solver (like a PLC), and a final element (a valve that shuts off the inflow).
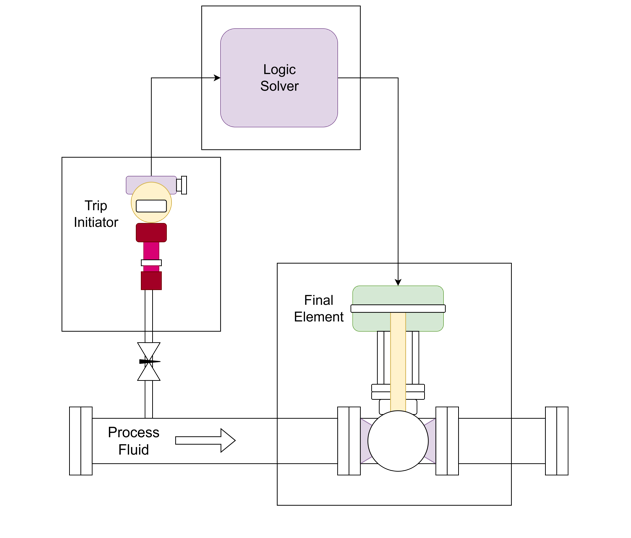
A random failure could occur in any of these hardware components. For instance, the level sensor might get stuck, the logic solver’s processor could fail, or the valve could seize.
The Hidden Flaw: Unmasking Systematic Failures
Systematic failures, in stark contrast to their random counterparts, are deterministic. They are inherent flaws or mistakes embedded within the system’s design, implementation, or operational procedures. A systematic failure will predictably and repeatedly occur under a specific set of circumstances. It’s not a matter of if it will fail when those conditions are met, but when.
These failures are often much harder to detect and can lie dormant for years, only to manifest when a particular and perhaps rare combination of inputs or conditions arises. Think of a software bug that only triggers when a specific sequence of commands is executed, or a design flaw that only becomes apparent under extreme process conditions.
Characteristics of Systematic Failures:
Deterministic: They are caused by a specific fault and will always occur if the right (or wrong) conditions are met.
Lifecycle-Related: They can be introduced at any stage of the safety lifecycle, from initial conception to decommissioning. This includes specification, design, installation, operation, and maintenance.
Software and Hardware: They can exist in both hardware (e.g., a design flaw in a circuit board) and software (e.g., a coding error).
Difficult to Quantify: You cannot assign a simple failure rate to a systematic flaw. Its “probability” is tied to the likelihood of the triggering conditions occurring.
Mitigated by Process and Scrutiny: The primary defense against systematic failures is a rigorous and well-documented engineering and management process.
Causes of Systematic Failures:
The origins of systematic failures are almost always rooted in human error or procedural deficiencies:
Specification Errors: Incomplete, ambiguous, or incorrect safety requirements.
Design Flaws: Errors in hardware or software design, including incorrect calculations, flawed logic, or poor choice of materials.
Software Bugs: Coding errors, logic flaws, or inadequate testing of software.
Installation and Commissioning Errors: Incorrect wiring, improper calibration, or failure to follow installation procedures.
Operational and Maintenance Errors: Bypassing safety functions improperly, incorrect maintenance procedures, or inadequate training of personnel.
Inadequate Management of Change: Failure to properly assess the safety implications of modifications to the system or process.
A Block Diagram Illustrating a Systematic Failure:
Let’s revisit our tank overfill protection SIF. A systematic failure wouldn’t be a random component failure, but a flaw in its very design or implementation.
Scenario: The logic solver is programmed to close the inlet valve when the level sensor reads “High.” However, the software developer made a mistake and programmed the logic to close the valve only if two consecutive “High” readings are received within one second. This was intended to prevent nuisance trips but wasn’t documented or properly analyzed.
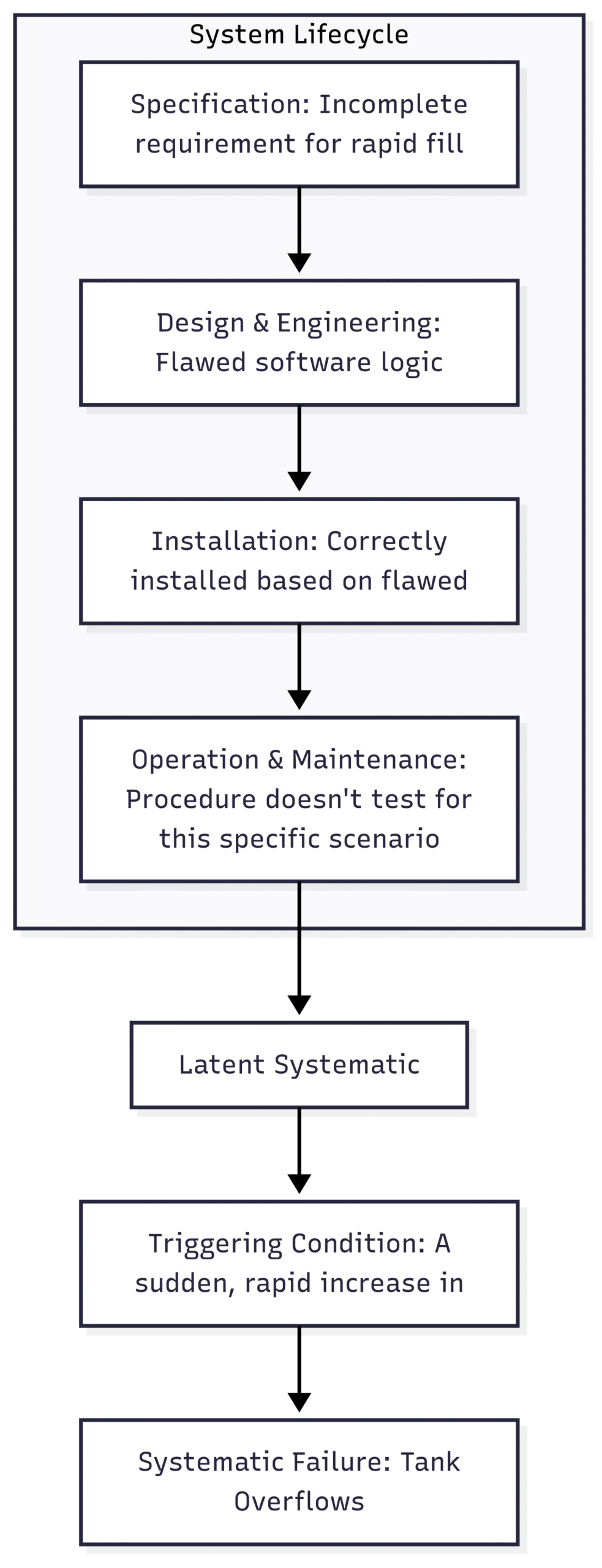
In this scenario, under normal, slow-filling conditions, the system appears to work perfectly. However, if there’s a sudden surge in the inflow (the triggering condition), the level could rise from below “High” to overflowing in less than a second. The flawed logic, waiting for a second “High” signal that never comes in time, will fail to close the valve, leading to a catastrophic failure.
The Great Divide: A Head-to-Head Comparison
Safety Integrity Level (SIL): The Unifying Framework
So, how do we build safety systems that are resilient to both the predictable unpredictability of random failures and the hidden dangers of systematic ones? This is where the Safety Integrity Level (SIL) comes in. SIL is a measure of the risk reduction provided by a safety function. It is a target level of performance that a safety function must achieve.
The international standard for functional safety, IEC 61508, and its sector-specific derivatives (like IEC 61511 for the process industry), define four SIL levels, from SIL 1 (the lowest level of risk reduction) to SIL 4 (the highest). The required SIL for a particular safety function is determined through a risk assessment of the process or system it is protecting.
Crucially, achieving a target SIL requires a two-pronged approach that addresses both random and systematic failures.
SIL and the Management of Random Failures
For random failures, SIL is defined by a quantitative target: the Probability of Failure on Demand (PFD) for low-demand mode systems (like our tank overfill example) or the Probability of Failure per Hour (PFH) for high-demand or continuous mode systems.
To meet these targets, engineers use techniques like:
Component Reliability Data: Using certified components with known and low failure rates.
Architectural Constraints: Employing redundancy (e.g., 1-out-of-2 or 2-out-of-3 voting logic) to ensure that the failure of a single component does not lead to the failure of the entire safety function.
Diagnostics: Implementing automated self-tests and diagnostics to detect failures as they occur. The Safe Failure Fraction (SFF) is a metric that quantifies the proportion of “safe” and “dangerous detected” failures to the total failures. A higher SFF is required for higher SILs.
Block Diagram: SIL and Random Failure Mitigation
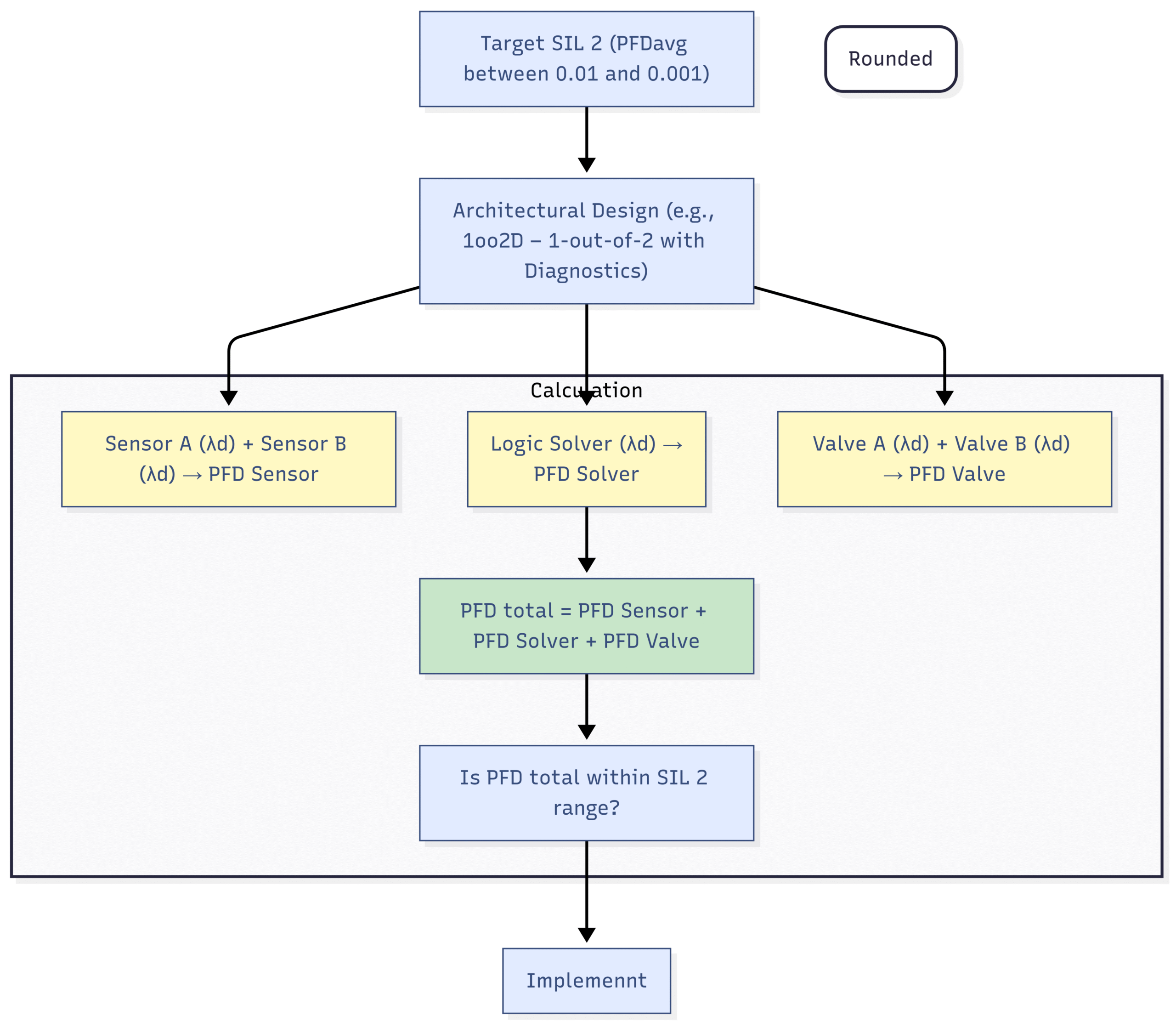
In this diagram, λd represents the dangerous undetected failure rate of each component. By using redundant components and calculating the overall PFD, engineers can verify that the design meets the quantitative requirements of the target SIL.
SIL and the Management of Systematic Failures
For systematic failures, a simple numerical target is not possible. You cannot calculate the “probability of a design flaw.” Instead, IEC 61508 and related standards prescribe a set of rigorous procedures and techniques that must be followed throughout the safety lifecycle. The higher the SIL, the more stringent these requirements become.
These requirements are designed to prevent the introduction of systematic failures and to detect and correct any that might slip through. This is often referred to as Systematic Capability (SC).
Key Measures to Control Systematic Failures:
Functional Safety Management: Having a documented plan for all safety lifecycle activities, including clear roles and responsibilities, and ensuring the competency of all personnel involved.
Verification and Validation: Independent checks and tests at each stage of the lifecycle to ensure that the outputs of that stage meet the requirements of the previous stage.
Strict Documentation and Change Management: Maintaining accurate and up-to-date documentation for all aspects of the safety system and having a formal process for managing any changes.
Proven in Use/Prior Use Justification: Using components and systems with a well-documented history of successful and safe operation in similar environments.
Structured Design and Development Methodologies: For software, this could include using specific coding standards, formal methods, and rigorous testing regimes.
Block Diagram: SIL and Systematic Failure Mitigation
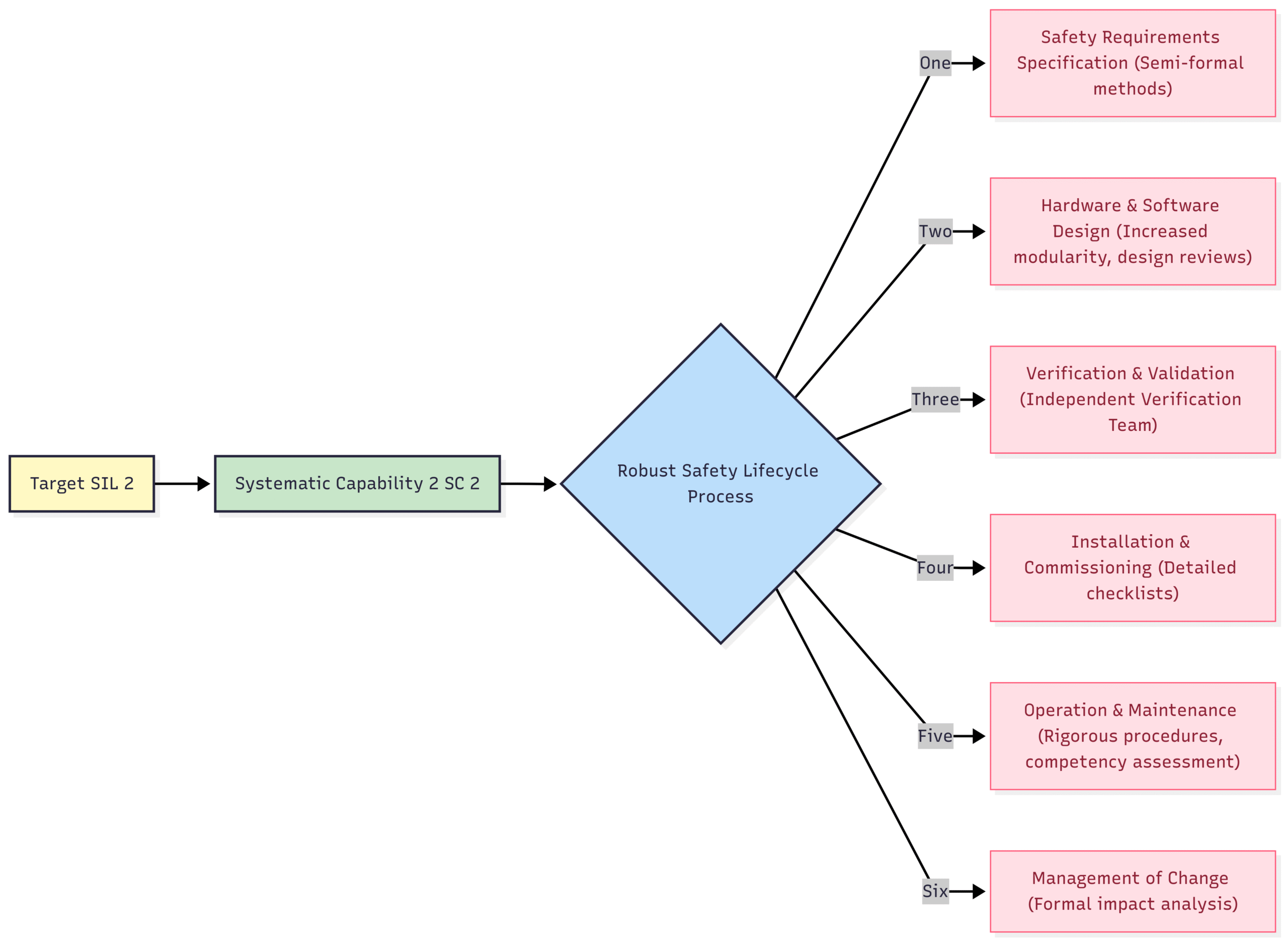
This diagram illustrates that achieving a certain SIL for systematic capability is not about a single calculation, but about the consistent and rigorous application of best practices throughout the entire lifecycle.
Conclusion: A Holistic Approach to Functional Safety
The journey to achieving true functional safety is a journey on two parallel paths: one that addresses the predictable randomness of hardware failures and another that tackles the ever-present potential for human and procedural error. A high SIL rating is not just a badge of honor for a safety system; it is a testament to the fact that both of these challenges have been met with the appropriate level of rigor and diligence.
By understanding the fundamental differences between random and systematic failures, and by embracing the structured, lifecycle-based approach mandated by standards like IEC 61508, organizations can build safety systems that are not only robust and reliable but are also demonstrably capable of performing their critical protective functions when they are needed most. In the high-stakes world of industrial safety, there is no room for error, whether it be a random glitch in a sensor or a hidden flaw in a line of code. A comprehensive understanding and management of both random and systematic failures are, therefore, not just best practice—they are an absolute necessity.